Ruby Ractors
Ruby Parallel Computing

Intro
Ractors (Ruby Actors) provide object safety and allow full parallel computing (uses as many CPUs as desired). This is very helpful with heavy CPU tasks that can be split into sensible independent tasks.
Ruby Core has threads, but fundamentally they offer only concurrency and are dangerous since they share objects (which requires a lot of care). Adding Mutex helps with safety, but you are still limited to concurrency and fundamentally will take as long as a single thread (but adds to responsiveness).
Other approaches can be found using:
However, I believe they are all fundamentally most effective for heavy IO tasks and not CPU tasks - and otherwise concurrent and restricted by Ruby’s Global Lock.
NOTE: Ractors are still considered experimental - as of Ruby 3.2 - so use at your own risk in production environments. BUT I HAVEN’T FOUND ANY PROBLEMS! BUT I have not used it in production.
Ractor Overview
- Components
- Life cycle
- Name (helpful in the context of supervision)
- Messages
- Object / Parallel Safety (objects must be immutable or otherwise not sharable)
Components
Ractors have several components
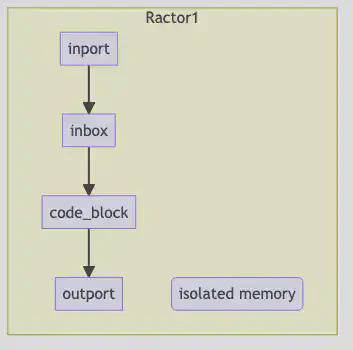
- An in-coming port (in-port) - is open while a
Ractor.receiveis waiting (blocking). - An in-coming mailbox - unlimited queue as long as the in-port is open - the mailbox’s queue is open as long.
- locally scoped code blocks (new & a bit odd - the compiler won’t allow variable names to be the same as external variables in the same class / thread - so when you pass it in you must rename it)
- locally scoped memory - object are copied here and must be thread / parallel safe (frozen and copied or copied and ownership transferred)
- An out-going port (out-port) - is open when a
Ractor.yieldis waiting (blocking)
Life-Cycle
A Ractor is basically alive as long as a port is open (however inspect seems to only report the status of the incoming port).
While a port is open the Ractor is blocking (waiting). When a message is received in the inbox, and the outgoing port is not blocked, then the Ractor will process the messages as soon as it is scheduled. When the Ractor has a result, but it has’t been taken then it can still recieve messages, but will not process them until the outgoing message has been picked-up (taken).
This is best clarified / demonstrated with code.
The following is an example of a short-lived Ractor that receives its input on initialization (thus the inbox is never opened). As soon as the Ractor is scheduled it does it’s work and returns the answer (the last line of a Ractor upon termination returns a result like other ruby code - which is collected with a take)
integer = 1
# automatically queues a message in the inbox
r1 = Ractor.new(integer, name: 'r1') do |i|
puts "Executing #{i} + 2"
i + 2
end
r1.inspect # => "#<Ractor:#1 r1 (irb):8 terminated>"
# the Ractor already did its work and the in-port was never opened (value was copied on initialization)
r1.send(1)
# `send': The incoming-port is already closed (Ractor::ClosedError)
# The Ractor outport is open, waiting for us to `take` the result
r1.take
# => 3
# after we retrieve the result the outport is closes too
r1.take
# `take': The outgoing-port is already closed (Ractor::ClosedError)
# now the Ractor `r1` is no longer usable / executable and will be garbage collected
A Ractor an easily be made to live indefinitely - with a loop. For this to work we need to make 2 changes - we need to open the incoming port with Ractor.receive and to collect the results with Ractor.yield (since the Ractor is no longer exiting, we need to do this to open the outgoing port and make the results available before exiting)
r1 = Ractor.new(name: 'r1') do
loop do
input = Ractor.receive
result = input + 2
puts "Executed - result will be: #{result}"
Ractor.yield(result)
end
end
r1.inspect
# => #<Ractor:#8 r1 (irb):12 blocking>
r1.send(1)
# Executed - result will be: 3
# => #<Ractor:#8 r1 (irb):41 blocking>
# we can add messages to the incoming queue
r1.send(2) # note this time it doesn't execute yet as we haven't taken the last result
# we fetch our first result and immediately the next message in the queue is executed
r1.take
# Executed - result will be: 4
# => 3
# now we get the last result, but nothing executes (since nothing is in the queue)
r1.take
# => 4
# we see that our Ractor is still waiting (blocking) for something to do
r1.inspect
# => "#<Ractor:#8 r1 (irb):41 blocking>"
# if we try to take now we will block our current thread too (the Ractor is waiting for an input and we are waiting for an answer)!
r1.take
Ractors ‘die’ if they experience an exception
integer = 'a'
# automatically queues a message in the inbox
r1 = Ractor.new(integer, name: 'doomed') { |i| i + 2 }
#<Thread:0x0000000104373ae8 run> terminated with exception (report_on_exception is true):
# (irb):16:in `+': no implicit conversion of Integer into String (TypeError) from (irb):16:in `block in <top (required)>'
# => #<Ractor:#4 doomed (irb):16 running>
# because the Ractor was build and immediately tried to process
# the return messages are in an odd order.
# actually checking the status confirms it died
r1.inspect
# => "#<Ractor:#9 r1 (irb):58 terminated>"
Named Ractors
Naming Ractors is optional - but helpful for supervision, so we know which Ractor has died and can restart the appropriate Ractor - Supervision will be explored later.
Here is code showing how to define a name on initialization and retrieve the Ractor’s name.
r1 = Ractor.new(name: 'r1') do
loop do
input = Ractor.receive
result = input + 2
puts "Executed - result will be: #{result}"
Ractor.yield(result)
end
end
=> #<Ractor:#11 r1 (irb):70 blocking>
r1.name
# => "r1"
Perfomance Comparison: Single-Threaded, Thread-Pool and Parallel Ractor
It is important to note that Ractors are not always better. In the interest of brevity I will not demonstrate when they are slower, but fundamentally when you are creating lots of objects and when the algorithm is faster than the time it takes to create Ractors and then execute them.
We will use recursion to calculate Fibonacci numbers - I needed something slow enough to take htop screen shots :)
Using the code: fibonacci recursion
def fibonacci(n)
ans = recursion(n)
result = "#{n} - #{ans}"
puts result
result
end
def recursion(n)
n <= 1 ? n : recursion( n - 1 ) + recursion( n - 2 )
end
We will individually calculate the Fibonacci numbers from 0 to 39 (too much bigger takes to long with this algorithm). Using injection to solve fibonacci is so fast that it’s not substantially faster in parallel:
def fibonacci(n) = (0..n).inject([1,0]) { |(a,b), _| [b, a+b] }[0]
and it was so fast that I didn’t have time to take htop screen shots. So I used recursion (on an M1 Mac - your times may vary if you use other technologies or more or fewer thread / ractors).
Traditional Ruby Single Treaded Code
Here is the text simple test code I put into an irb session.
def fibonacci(n)
ans = recursion(n)
result = "#{n} - #{ans}"
puts result # its nice to see the results as you go
result
end
def recursion(n)
n <= 1 ? n : recursion( n - 1 ) + recursion( n - 2 )
end
rounds = 40
pool_size = 6
results = []
# Single Thread
t1 = Time.now
rounds.times do |i|
# trigger the calculations and collect our results
results << fibonacci(i)
end
puts "Single thread - duration #{Time.now - t1}"
pp results
- time: 17.414451 seconds
- results are returned in a sequential order.
We get an output something like:
0 - 0
1 - 1
2 - 1
3 - 2
4 - 3
5 - 5
6 - 8
...
Single thread - duration 17.414451
Simple Multi-Threaded Ruby
Simple Thread Pool Implmentation http://www.java2s.com/Code/Ruby/Threads/Getthevaluereturnedfromathread.htm
t1 = Time.now; threads = []
results = [37].cycle(10).map { |i| Thread.new { [i, fib(i)] }.value }
puts "10 Ruby Threads Sequential - duration #{Time.now - t1}" # duration 24.546575
https://stackoverflow.com/questions/1383390/how-can-i-return-a-value-from-a-thread-in-ruby
# 10 Threads
t1 = Time.now; threads = []
[37].cycle(10).each { |i| threads << Thread.new { Thread.current[:results] = [i, fib(i)] } }
results = threads.map { |t| t.join; t[:results] }
puts "10 Ruby Threads Sequential - duration #{Time.now - t1}" # duration 24.546575
Object Oriented Thread Pool Implmentation
https://rossta.net/blog/a-ruby-antihero-thread-pool.html
I decided to use a simple Naive Thread Pool - (this isn’t an article about Thread Pools). The following is the code entered into irb.
def fibonacci(n)
ans = recursion(n)
result = "#{n} - #{ans}"
puts result
result
end
def recursion(n)
n <= 1 ? n : recursion( n - 1 ) + recursion( n - 2 )
end
# ThreadPool- Naive Source: https://rossta.net/blog/a-ruby-antihero-thread-pool.html
class ThreadPoolNaive
def initialize(size:)
@pool = []
end
def schedule(*args, &block)
@pool << Thread.new { block.call(args) }
end
def shutdown
@pool.map(&:join)
end
end
rounds = 40
pool_size = 4
results = []
# Thread Pool
pool = ThreadPoolNaive.new(size: pool_size)
t1 = Time.now
rounds.times do |i|
pool.schedule {
results << fibonacci(i)
}
end
pool.shutdown
puts "Concurrent Threads with #{pool_size} threads - duration #{Time.now - t1}"
pp results
Using 4 Threads we see that again time is basically the same as Single Threaded - I believe this has to do with Ruby’s ‘Global Lock’.
- Time: 17.351042 second
- the results are returned in no particular order (thus if order is important an extra sort step will be needed).
We get an outputs similar to:
0 - 0
2 - 1
3 - 2
31 - 1346269
32 - 2178309
6 - 8
7 - 13
...
Concurrent Threads with 4 threads - duration 17.351042
Ruby Parallel Ractor Code
Now let’s check the performance in parallel with Ractors. Here is the code entered into irb
Let’s open htop and see how what our system resources look like:
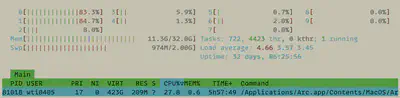
Once we start our code we see that the system load increases by 4 CPUs - so we are truly running in parallel:
def fibonacci(n)
ans = recursion(n)
result = "#{n} - #{ans}"
puts result # its nice to see the results as you go
result
end
def recursion(n)
n <= 1 ? n : recursion( n - 1 ) + recursion( n - 2 )
end
rounds = 40
pool_size = 4
results = []
# generate a Ractor that will act as a worker pool
pool = Ractor.new {
loop { Ractor.yield(Ractor.receive) }
}
# generate Workers that will do the work
workers = (1..pool_size).map do |i|
Ractor.new(pool) do |input_pipe|
loop { Ractor.yield(fibonacci(input_pipe.take)) }
end
end
t1 = Time.now
rounds.times { |i| pool.send(i) } # send requests
rounds.times {
answer = Ractor.select(*workers)
# returns: [#<Ractor:#6 r4 slow_ractor_pool.rb:18 blocking>, "3 - 2"]
results << answer.last # .last because we only want the result
}
puts "Parallel Ractors - pool size: #{pool_size} - duration #{Time.now - t1}"
pp results
- Time: 8 seconds (considerably faster with 4 Ractors)
- The results are not sequential (so again if order is important, than a sort will be necessary)
The output looks something like:
2 - 1
0 - 0
1 - 1
3 - 2
6 - 8
4 - 3
8 - 21
...
Four Parallel Ractors - pool size: 4 - duration 7.912549
Ruby Consume Pool (Full CPU usage)
def fib n
if n < 2
1
else
fib(n-2) + fib(n-1)
end
end
max = 39
rs = max.downto(1).map { |i| i }.map do |i|
Ractor.new i do |i|
[i, fib(i)]
end
end
t1 = Time.now
until rs.empty?
r, v = Ractor.select(*rs)
rs.delete r
p answer: v
end
puts "Parallel Ractors - full cpu usage - duration #{Time.now - t1}"
Only 1 second faster, but releases / consumes the Ractors as the job progresses. Returns the answers in the order submitted
Ractor Communication
Ractors have two ways to communicate:
- push - traditional
actorstyle communication (send -> receive) – the Ractor receives messages in its messagein-box - pull - Rendezvous Style - we block on the output and wait for results using
take
It’s important to note that Objects must be transferred (ownership) or copied (Frozen) - they must be thread safe! This is an important aspect of the design. with simple objects this is handled automatically, however, when transferring helper classes, etc this this can be important (will be demonstrated later).
Ractor Communications is the basis for the interesting designs that are possible. Communication is heavily dependent on the opening of incoming and outgoing ports. Please be sure that section makes sense.
Push Communication
Push Communication is as it sounds - we are pushing sending data to another Ractor’s open incoming port. The interaction between 2 Ractors (or the Main Ractor / Thread) looks conceptually something like the following:
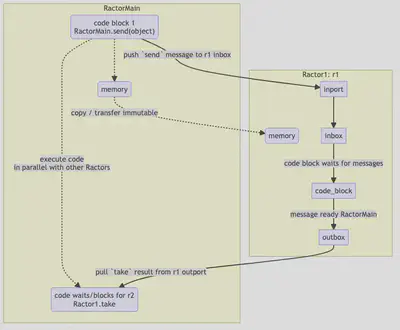
Push Code & Flow
To receive messages in the incoming port and mailbox we must invoke: Ractor.receive within our Ractor. Let’s see what this looks like in code.
First, we will demonstrate that this ‘copies’ the object - we will check the passed object’s id and see that they differ.
Second, we see that we open the incoming port for push communication with Ractor.receive
Third, we see we incoming and outgoing port are only ‘open’ for one transaction (since we have not placed our Ractor behavior in a loop)
Note, new in Ruby 3.2 it seems that the compiler no longer allows internal variable names object_in to have the same name as an external variable object, I am not sure why this is the case since in theory they are in different namespaces.
object = 'Hi'
object.object_id # 25940
r1 = Ractor.new do
# ruby compiler doesn't allow the same name in a Ractor as an external object!
object_in = Ractor.receive
p object_in.object_id # 47640
object_in # result given to the outbox
end
# we push `send` our message
r1.send(object)
# 47640 # print executes
# given there is no loop the incoming port closes after the first message
r1.send('Hoi')
# `send': The incoming-port is already closed (Ractor::ClosedError)
# collect our result with:
r1.take
# 'Hi'
# again, without a loop Ractors close the outbox when emptied
r1.take
# `take': The outgoing-port is already closed (Ractor::ClosedError)
NOTE: take and send are blocking calls so you can easily create deadlock by you calling a take in your main Thread/Ractor before sending that Ractor information. You can see this deadlock with the following code and will need to use ctrl-c to end the deadlock.
r1 = Ractor.new do
obj = Ractor.receive # gets sent information
obj # result available in the outport
end
rt.take # waits for the outbox, but has not input so you will wait forever!
# ctrl-c
Pull Communication (Rendezvous Style)
Pull - ’take’s objects Safely
This is pulling takeing information out of a Ractors outgoing port. Conceptually, this looks something like:
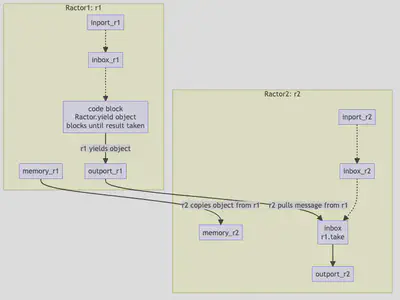
Pull communication Flow
We have demonstrated pulling takeing information from a Ractor that has already done a calculation and is waiting to terminate in the previous code.
So here I will demonstrate how to open the outgoing port in a running Ractor - usually one within a loop.
This is done with the Ractor.yield(return_object) command. Here is an example without an infinite loop and one where we don’t open the incoming port. We are just queueing 3 results
r1 = Ractor.new do
3.times { |i| Ractor.yield(i) }
end
3.times { p r1.take }
# 0
# 1
# 2
# => 3 # like normal ruby code the last value is returned
# because 3 was the last result will also be returned
r1.take
# => 3
r1.take # now the outbox is empty
# `take': The outgoing-port is already closed (Ractor::ClosedError)
A Ractor with a loop puts the last result in the outbox (or another value if it has an explicit return)
r1 = Ractor.new do
3.times { |i| Ractor.yield(i) }
:r1_done
end
3.times { p r1.take }
# 0
# 1
# 2
# => :r1_done
r1.take
# => :r1_done
NOTES:
- final results of a Ractor block and placed in the outgoing port via
Ractor.yieldhave a queue size of ONE value. Unlike the incoming port which has a infinite queue. - once the outgoing port has a value the Ractor is ‘blocked’ waiting for the result to be
taken. Thus if we aren’t careful we can create deadlock by expecting to take a result in our main thread when the Ractor has no value to offer. - Once the Ractor has closed its outgoing port (given all its values away) and the incoming port is also closed (not accepting any new inputs), then the Ractor is ’terminated’. Using closed incoming or outgoing Ractor ports will result in an exception.
Ractor Usage - Practical Design Fundamentals
The basic design ideas are:
- queue consumption
- pipelines
- pools
- exceptions
- supervision
With these we can create Robust parallel computing structures.
Consume Queue
Often we might have a big job to do and then we are done. The drawback is that this system uses as many CPUs as available. The benefit is that it is a temporary construction. When the work is completed the Ractors are deleted.
To queue lots of work and retrieve those that are completed,
we use a new method select. This waits for completed Ractors to
open their outgoing port to collect the results.
max_fib = 39
def fib(n) = n < 2 ? 1 : fib(n-2) + fib(n-1)
# we create an Array of Ractors to do the work needed.
work_queue = (1..max_fib).map do |i|
Ractor.new(i) { |i| [i, fib(i)] }
end
t1 = Time.now
# we wait here in this loop for our queued work to finish (using `select`)
until work_queue.empty?
# 'select' returns both the Ractor and the value
terminated_ractor, computed_value = Ractor.select(*work_queue)
# the Ractor is now terminated - so we remove it from our work queue
work_queue.delete terminated_ractor
p answer: computed_value
end
puts "Parallel Ractors - full cpu usage - duration #{Time.now - t1}"
This is a great way to accomplish a lot of work that can be parallelized.
Pipeline
This is helpful when there are multiple steps to accomplish in a task.
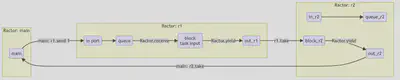
def increment(n) = n + 1
r1 = Ractor.new do
loop do
incoming_r1 = Ractor.receive
incremented_once = increment(incoming_r1)
Ractor.yield(incremented_once)
end
end
r2 = Ractor.new(r1) do |r1|
loop do
incoming_r2 = r1.take
incremented_twice = increment(incoming_r2)
Ractor.yield(incremented_twice)
end
end
# Main Thread (Main Ractor)
r1.send(1)
r2.take
# => 3 - since 1 was incremented twice
Pooling (Load Balancing)
Pooling builds upon pipelines.
- First we build a pool (a supervisor - without error handling)
- Then we add workers in a pipeline
To use a pooling we:
- push (
send) our inputs into the pool (supervisor), which queues up messages in the worker’s inboxes - to wait for multiple Ractors
Ractor.select(*workers)orRactor.select(r1, r2)instead ofr1.takewhich only waits for one specific Ractor *r1).
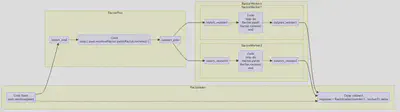
We need a new command .select for this.
def fibonacci(n)
ans = (0..n).inject([1,0]) { |(a,b), _| [b, a+b] }[0]
result = "#{n} - #{ans}"
puts result
result
end
pool = Ractor.new do
loop do
input = Ractor.receive
Ractor.yield(input)
end
end
# 4 workers
workers = (1..4).map do |i|
Ractor.new(pool, name: "r#{i}") do |p|
loop do
input = p.take # from pool
output_value = fibonacci(input)
Ractor.yield(output_value)
end
end
end
results = []
# send 8 Requests
40.times { |i| pool.send(i) }
# notice the first 4 values are computed immediately, and then it stops since the outports are full (queue of 1)
# collect our Results - wait for multiple
40.times { results << Ractor.select(*workers) }
# now that we collect the results the inboxes will be processed
# if we are uncertain how
# notice select returns the Ractor that did the processing and the result
pp results
# collect just the results and sort them since they are processed in any random order
pp results.map { |r| r.last }.sort
This is a great technique for log running services (although supervision - covered next will make it even more robust). Shown later.
This is also great since when we create a pool - we control how many resources (CPUs) we will use.
One disadvantage of this approach is that if the Ractor experiences an exception, the all the queued messages sent into the pool are quickly queued into the worker inboxes and that queue worked is then lost.
Exceptions and Supervision
By understanding Exceptions we can also create supervision - restore crashed Ractors
Exceptions Trapping
On Send
def task(char) = char + '2'
r1 = Ractor.new(name: 'r1') do
task(Ractor.receive)
end
r1.send('1')
p r1.take # => '12'
# without loop after first usage it closes
begin
r1.send('2')
rescue Ractor::ClosedError => e
p e
p e.cause
p e.ractor
end
# => #<Ractor::ClosedError: The incoming-port is already closed>
p r1
#<Ractor:#2 r1 (irb):3 terminated>
On Take - we throw RemoteError and we can gather a little more info.
r1 = Ractor.new(name: 'r1') do
loop { task(receive) }
end
# if wrong type it closes with an error
begin
r1.send(1)
p r1.take
rescue Ractor::RemoteError => e
p e #<Ractor::RemoteError: thrown by remote Ractor.>
p e.cause #<TypeError: String can't be coerced into Integer>
p e.ractor #<Ractor:#22 r1 (irb):236 terminated>
end
r1.send('2')
# => #<Ractor::ClosedError: The incoming-port is already closed>
Exception Propagation
If we crash r1 it will propagate the exception to r2
def increment1(n) = n + 1
def increment2(n) = n + 2
r1 = Ractor.new(name: 'r1') do
loop do
incoming_r1 = Ractor.receive
incremented_once = increment1(incoming_r1)
Ractor.yield(incremented_once)
end
end
r2 = Ractor.new(r1, name: 'r2') do |r1|
loop do
incoming_r2 = r1.take
incremented_twice = increment2(incoming_r2)
Ractor.yield(incremented_twice)
end
end
# Main Thread (Main Ractor)
r1.send(1)
r2.take # => 4
r1.send(2)
# if we don't collect (take) our result it gets lost with the propagated crash
r1.send('c')
#<Thread:0x00000001081260c0 run> terminated with exception (report_on_exception is true):
r2.take # <internal:ractor>:698:in `take': thrown by remote Ractor. (Ractor::RemoteError)
Supervision (Retry)
If we crash on a send - then we may be able to retry and continue if we know whats wrong with the data and can fix it.
def task(char) = char + '2'
def r1_init = Ractor.new(name: 'r1') { loop { Ractor.yield task(Ractor.receive) } }
r1 = r1_init
r1.send('1')
r1.take # => '12'
input = 1
begin
r1.send(input)
p r1.take #<Thread:0x0000000103feca28 run> terminated with exception (report_on_exception is true):
rescue Ractor::RemoteError => e
pp e.cause
pp e.ractor
pp e.ractor.name
# restart ractor
r1 = r1_init
# retry 'sending' & 'taking' after input coercion
input = input.to_s
retry
end
# #<TypeError: String can't be coerced into Integer>
#<Ractor:#2 r1 (irb):21 terminated>
# "12"
p r1
#<Ractor:#3 r1 (irb):21 blocking>
Supervision (Remove & Recreate)
When a worker in a pool dies when we execute while select - then we may need to remove the dead worker and create a new worker.
Note: retry doesn’t help us when the send and take are not paired together.
MAX_CPUS = 4.freeze; MAX_FIB_NUM = 39.freeze
def fib(n) = n < 2 ? 1 : fib(n-2) + fib(n-1)
def make_pool = Ractor.new { loop { Ractor.yield(Ractor.receive) } }
def make_worker(pool)
Ractor.new(pool) do |p|
loop {
input = p.take
fib_num = fib(input)
result = [input, fib_num]
Ractor.yield(result)
}
end
end
def make_workers(pool, count)
(1..count).map do |i|
make_worker(pool)
end
end
def send_work(input, pool)
Array(input).each do |i|
pool.send(i)
end
end
def collect_results(input, pool, workers)
results = []
input.count.times do
begin
worker, answer = Ractor.select(*workers)
results << answer
rescue Ractor::RemoteError => e
worker = e.ractor
pp worker
workers.delete(worker)
# restore worker
workers << make_worker(pool)
end
end
results
end
def run_fib(input, pool, workers)
send_work(input, pool)
collect_results(input, pool, workers)
end
pool = make_pool
workers = make_workers(pool, 4)
pp workers
input_list = [29, 28, 27, 26, 25]
answers = run_fib(input_list, pool, workers)
pp answers.count
pp answers
pp workers # workers are the same as above
input_list = [24, 23, '21', '22', 20]
answers = run_fib(input_list, pool, workers)
pp answers.count
pp answers
pp workers # 2 workers now have higher numbers
# We can keep using our pool even after some crashed
input_list = [34, 33, 32, 31, 30]
answers = run_fib(input_list, pool, workers)
pp answers.count
pp answers
pp workers # workers are the same as above
Notice we now get answers to all our valid inputs and all Ractors have been newly created & are blocking - waiting for work.
note: I experienced problems recreating Ractors with the same name as the crashed one).
Practical Usage
In the comparison toward the beginning we a pipeline with a supervisor and a pool.
Example Web Server Pool (with supervision)
Source mostly from: https://kirshatrov.com/posts/ractor-web-server-part-two/
NOTE: Ractor.receive(pipe, move: true) moves (transfers the ownership of the object) instead of the default copying the object
# source: https://kirshatrov.com/posts/ractor-web-server-part-two/
require 'webrick'
def respond(c, req)
# process request
path = req.path
query = req.query
body = req.body
# log request
puts
puts req.inspect
puts
puts "path:"
puts path.inspect
puts "query:"
puts query.inspect
puts "Body:"
puts body.inspect
puts "=" * 150
# respond to Connection
c.print "HTTP/1.1 200\r\n"
c.print "Content-Type: text/html\r\n"
c.print "\r\n"
c.print "<h1>Hello #{query['name'] || 'world'}</h1>"
c.print "<h2>Your path: #{path}</h2>"
c.print "<br>"
c.print "<hr>"
c.print "<br>"
c.print req.inspect
end
# need to Freeze WEBrick objects that need to be passed - there is a PR to fix this, but not yet merged.
# PR: https://github.com/ruby/webrick/pull/65
Ractor.make_shareable(WEBrick::Config::HTTP)
Ractor.make_shareable(WEBrick::LF)
Ractor.make_shareable(WEBrick::CRLF)
Ractor.make_shareable(WEBrick::HTTPRequest::BODY_CONTAINABLE_METHODS)
Ractor.make_shareable(WEBrick::HTTPStatus::StatusMessage)
def make_pipe
Ractor.new do
loop do
Ractor.yield(Ractor.receive, move: true)
end
end
end
def make_worker(pipe_line)
Ractor.new(pipe_line) do |pipe|
loop do
# capture input
s = pipe.take
# process input
req = WEBrick::HTTPRequest.new(
WEBrick::Config::HTTP.merge(RequestTimeout: nil)
)
req.parse(s)
respond(s, req)
s.close
end
end
end
def make_workers(pipe, cpu_count)
cpu_count.times.map { make_worker(pipe) }
end
def make_listener(pipe_line)
Ractor.new(pipe_line) do |pipe|
server = TCPServer.new(8080)
loop do
conn, _ = server.accept
pipe.send(conn, move: true)
end
end
end
CPU_COUNT = 4.freeze
pipe = make_pipe
workers = make_workers(pipe, CPU_COUNT)
listener = make_listener(pipe)
loop do
begin
Ractor.select(listener, *workers)
# Worker Supervision
rescue Ractor::RemoteError => e
# identify crashed worker
worker = e.ractor
# remove crashed worker
workers.delete(worker)
# restore a new worker
workers << make_worker(pipe_line)
end
end
if we run this code in IRB - we see we have a very simple web-server with 4 parallel workers
if we go to http://localhost:8080/ - we should see:
Hello world
Your path: /
# along with all the session info
If we go to http://localhost:8080/hoi?name=bill - we should see:
Hello bill
Your path: /hoi
# along with all the session info
Tech (Ruby) Kafi Presentation
https://www.puzzle.ch/de/blog/articles/2023/02/22/tech-kafi-ruby-ruby-memory-optimierung
Slides
Questions and Answers (from Ractor Author - Koichi Sasada)
- Road Map - (Dec 2023 - Ruby 3.3?) Ideally
The following are needed:
a. Stabilize API - especially for the select command (he’s looking for feedback) a new API Ractor::Selector. If you have a comment, it is great. https://github.com/ruby/ruby/pull/7371 I’m especially thinking about whether “auto removing” is good or not (or should be options). https://github.com/ruby/ruby/pull/7371files#diff-2be07f7941fed81f90e2947cdd9a91a5775d0c94335e8332b4805d264380b255R446
b. MaNy Project (using the M:N algorithm - he has a talk in Japanese) - ractors should scale to multiple thousands and still run (be scheduled) efficiently (currently effective scheduling is limited to about 300)
c. Efficient memory usage - at scale - especially for long running Ractors - He isn’t promising Dec 2023 release - but its his goal.
- regarding Data Copying - I didn’t fully understand - but here is his answer (hopefully I got the question correct) - it can be slow, but no martialing is used
Some objects (object tree structures for example) takes long time to make them shareable. If objects are immutable (sharable), you don’t need to make marshal data.
Copying complex objects is slow:
For example, Node.new(Node.new(Node.new(....)))) it makes tree structure objects and even if they are frozen, to check they are all frozen, it needs to traverse the tree.
For example, Node.new(.... in deep ..., Node.new("str") ...) creates almost frozen, but 1 mutable (unshareable) string object. The tree is not a shareable object(s).
Unfortunately, ‘moving’ objects is also slow when complex - especially when deeply nested.
- Garbage collection of Ractors - there is no way to explore unreferenced Ractors, but the will be garbage collected when they finish running.
(1) no references to the ractor AND (2) the ractor is already terminated
- Back-pressure controlling message flows at high volume - forcing senders to slow down. (I don’t have Rafael’s email - can someone forward this to him)
He is interested, but not familiar with it an will consider it if I can send him enough information to consider a plan)
I think it will be difficult since OTP has 2 ways to send messages - send with reply and without reply - and if you require reply and slowly answer the reply that signals to the client they need to slowdown, Currently, factors only have send w/o reply.
If someone knows / has an design link for OTP backpressuree Ill send it along.
I’ll add these answers to the talk and the blog.
If you have more questions - I’ll gladly forward the otherwise here is his email if you want to ask directly - sasada@gmail.com
Ractor Presentations
- RubyKafi @ Puzzle - https://github.com/btihen/ruby_kafi_ractor_talk
- Ractor Demonstration - Koichi Sasada - https://www.youtube.com/watch?v=0kM7yFM6Dao
- https://www.youtube.com/watch?v=40t8EPpnujg
- RubyConf 2021 - Learning Ractor with Raft by Micah Gates - https://www.youtube.com/watch?v=_O3NBm_C3rM
- RubyConf 2021 - Parallel testing with Ractors - Putting CPU’s to work by Vinicius Stock - https://www.youtube.com/watch?v=wI7NgPJO7Zg
- Ruby, Ractor, QUIC / Yusuke Nakamura @unasuke - https://www.youtube.com/watch?v=9da7QccHXV4
Resources
https://www.fastruby.io/blog/ruby/performance/how-fast-are-ractors.html
https://dev.to/doctolib/learn-about-ractors-and-build-a-mini-sidekiq-3ba2
https://blog.appsignal.com/2022/08/24/an-introduction-to-ractors-in-ruby.html
https://www.dmitry-ishkov.com/2021/07/http-server-in-ruby-3-fibers-ractors.html
https://andresakata.medium.com/background-job-processing-using-ractor-ruby-3-41c7956d14a0
Async
- https://github.com/socketry/async
- https://brunosutic.com/blog/async-ruby
- https://www.youtube.com/watch?v=T8YF8qBoBAA
- https://www.youtube.com/watch?v=pzpH_ND-CQM
- https://www.codeotaku.com/journal/2018-06/asynchronous-ruby/index
- https://socketry.github.io/async/guides/getting-started/index.html
- https://medium.com/double-pointer/concurrency-in-ruby-async-programming-part-1-9db33073baf9
- https://medium.com/double-pointer/concurrency-in-ruby-async-programming-part-2-ff226fb54cfe
Threads & Thread Pooling
- https://github.com/meh/ruby-thread#pool
- https://www.rubyguides.com/2015/07/ruby-threads/
- https://rossta.net/blog/a-ruby-antihero-thread-pool.html
- https://stackoverflow.com/questions/32593289/ruby-thread-pooling-what-am-i-doing-wrong
- https://stackoverflow.com/questions/1383390/how-can-i-return-a-value-from-a-thread-in-ruby
Bill Tihen
Developer, Data Enthusiast, Educator and Nature’s Friend
very curious – known to explore knownledge and nature